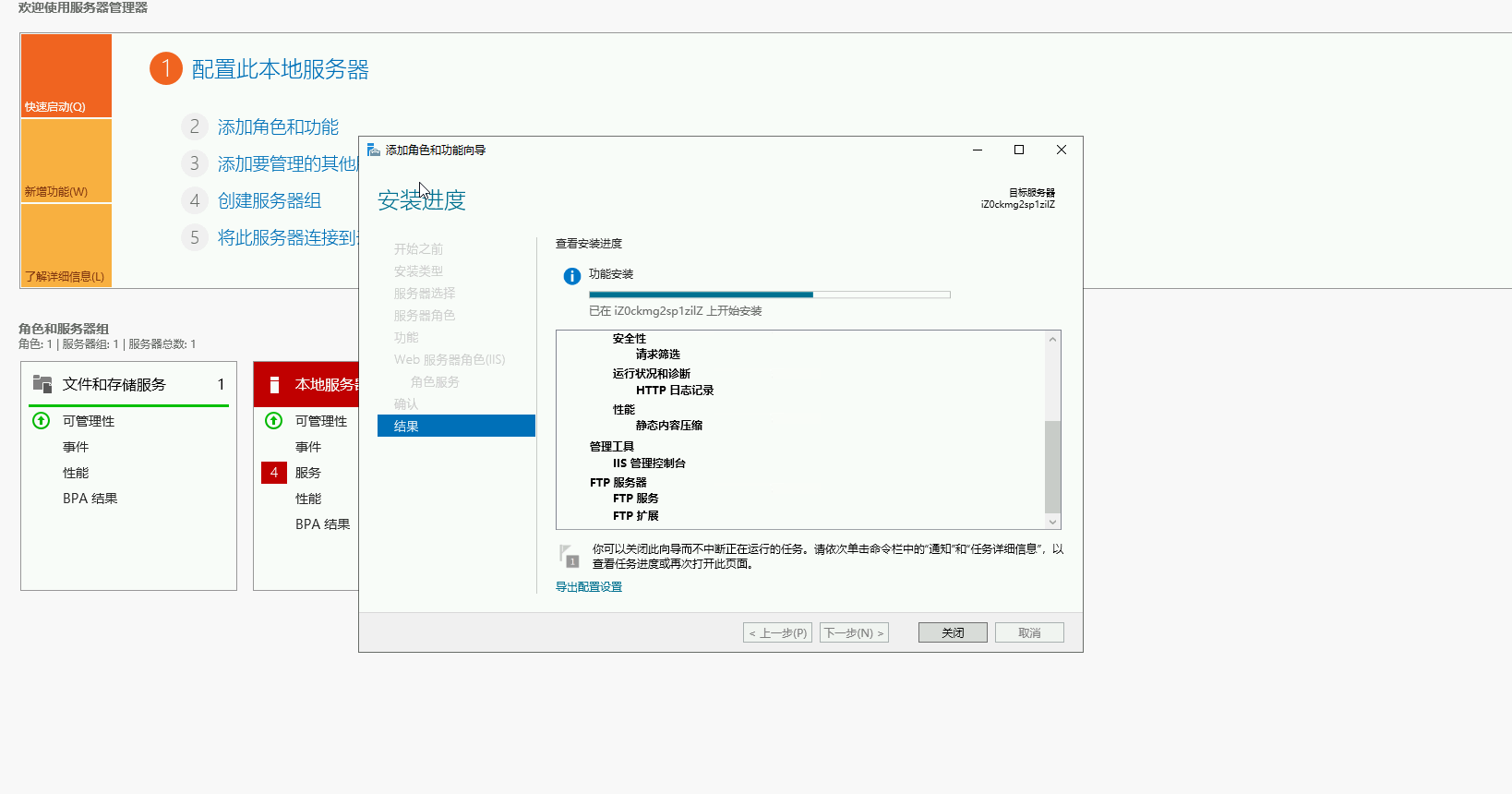
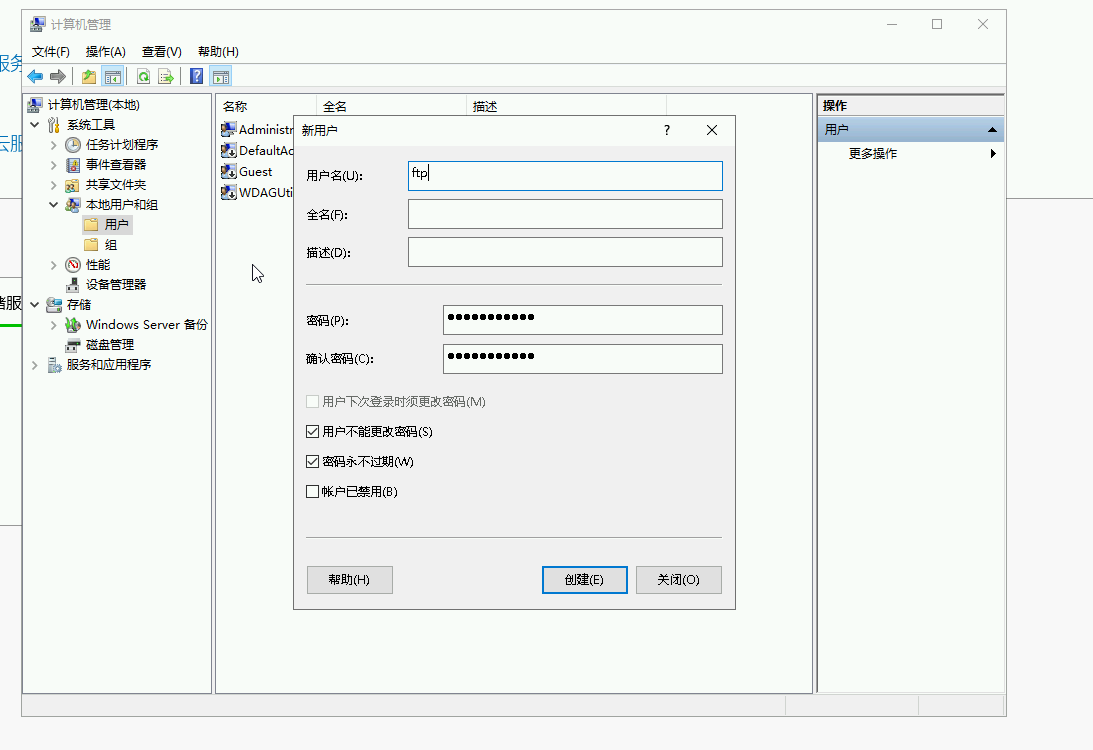
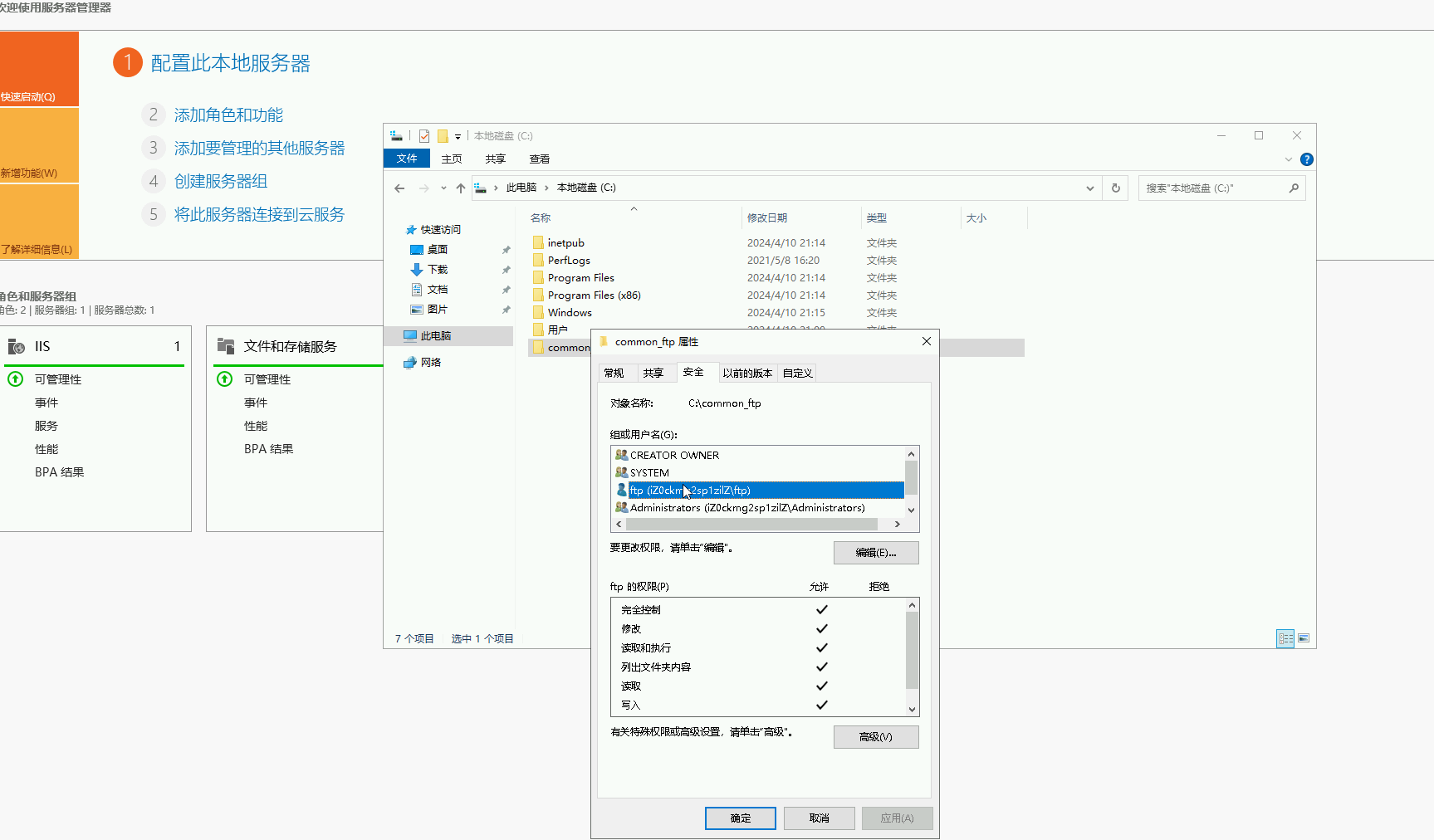
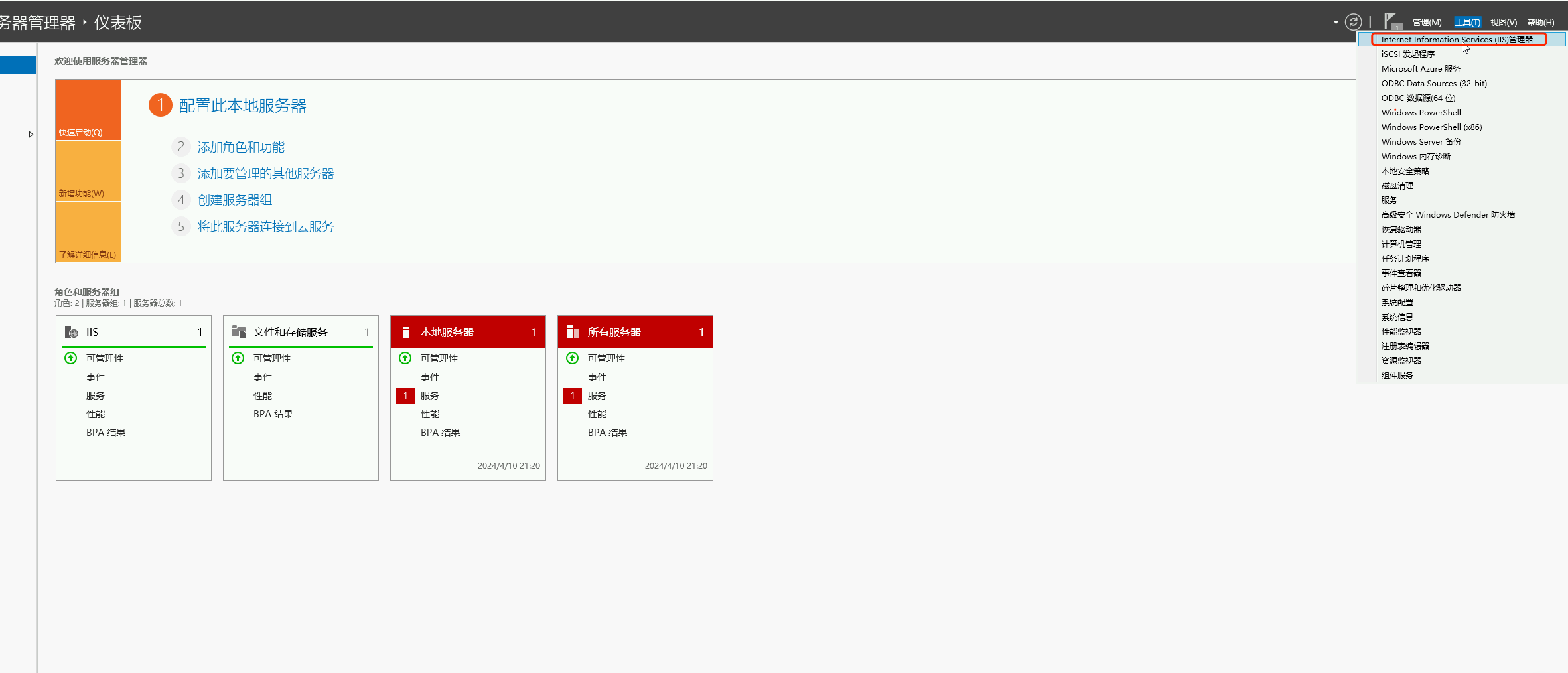
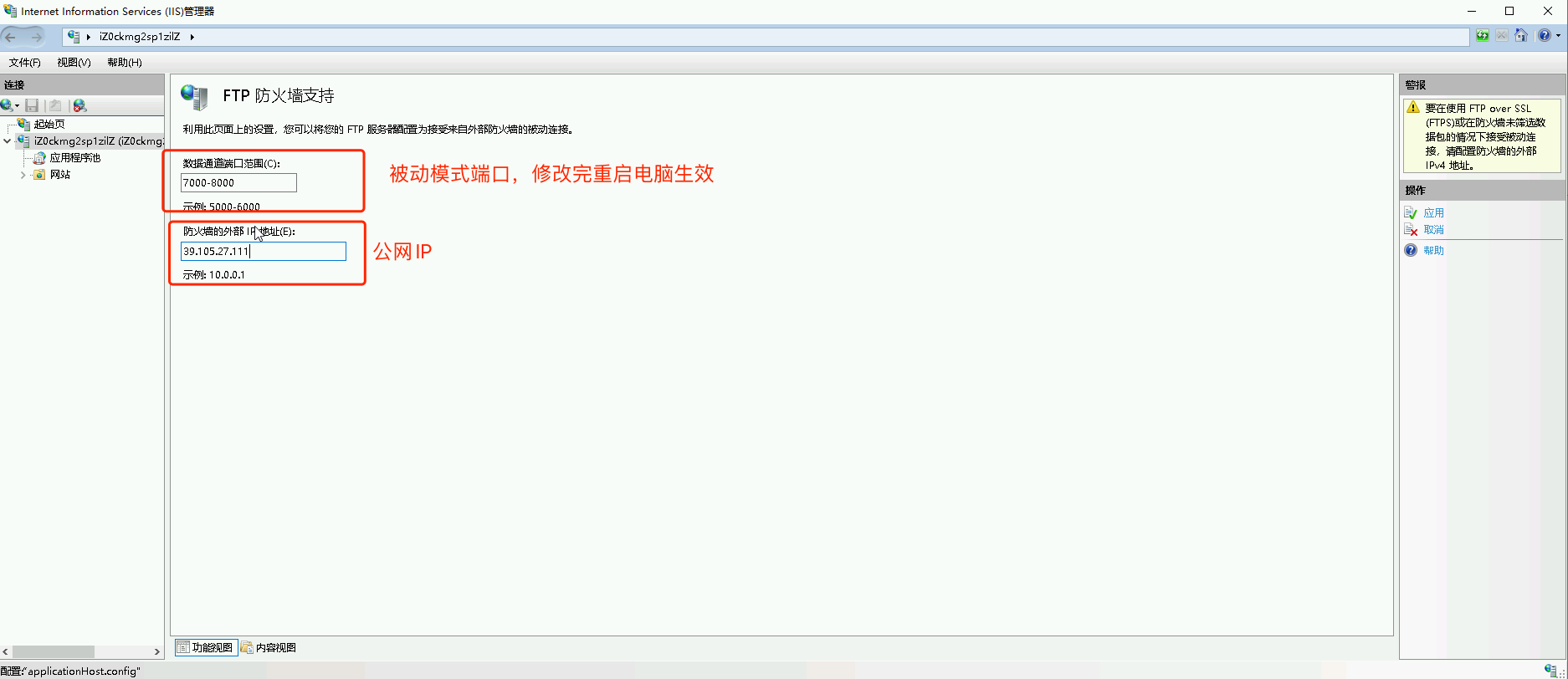
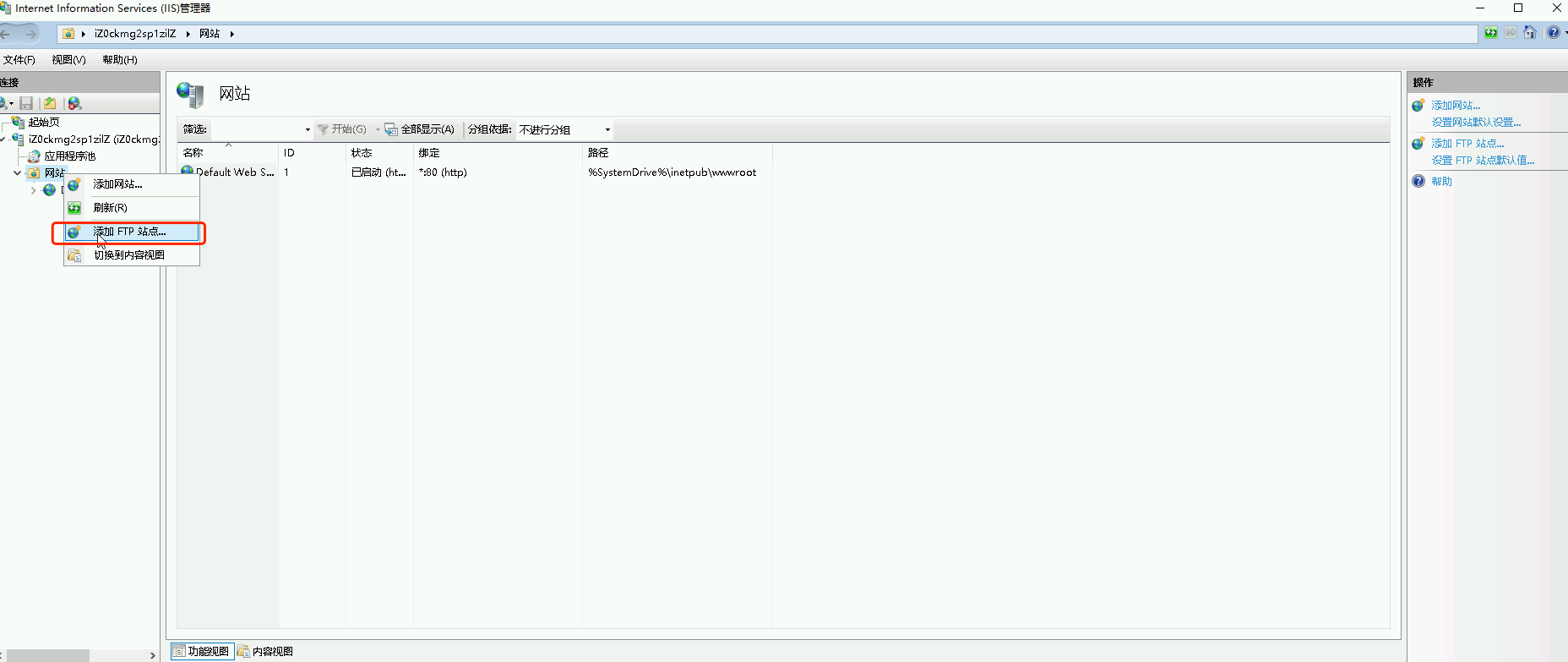
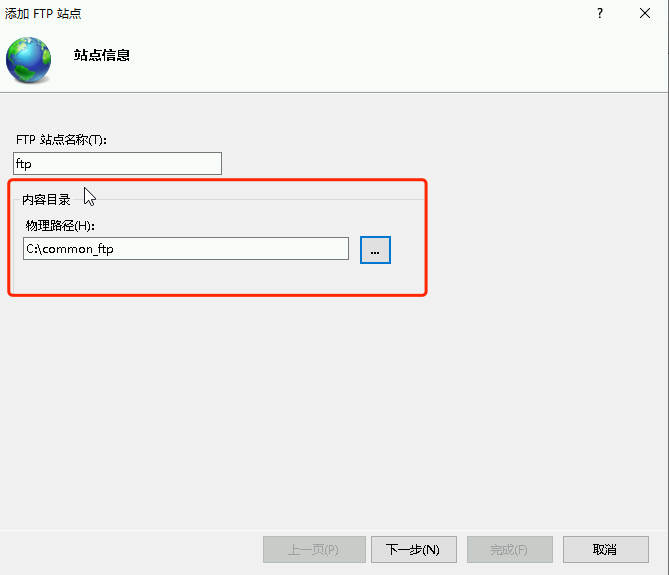
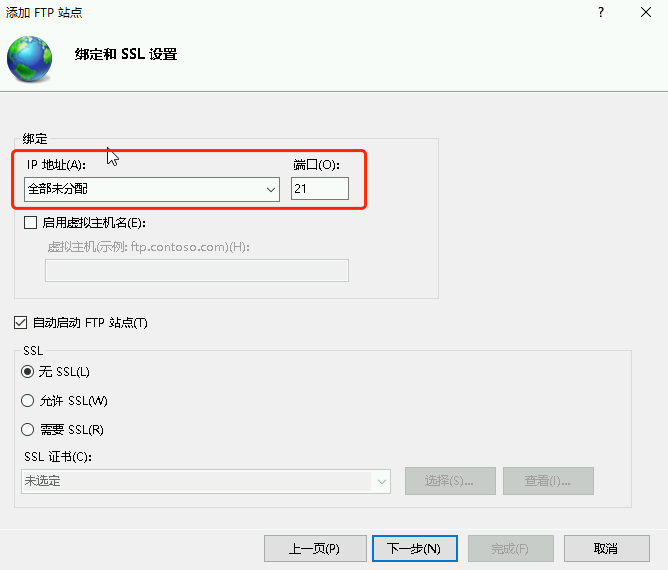
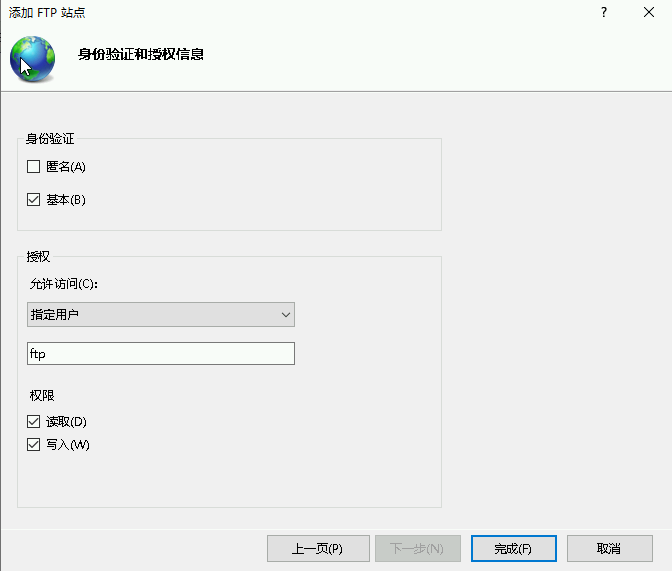
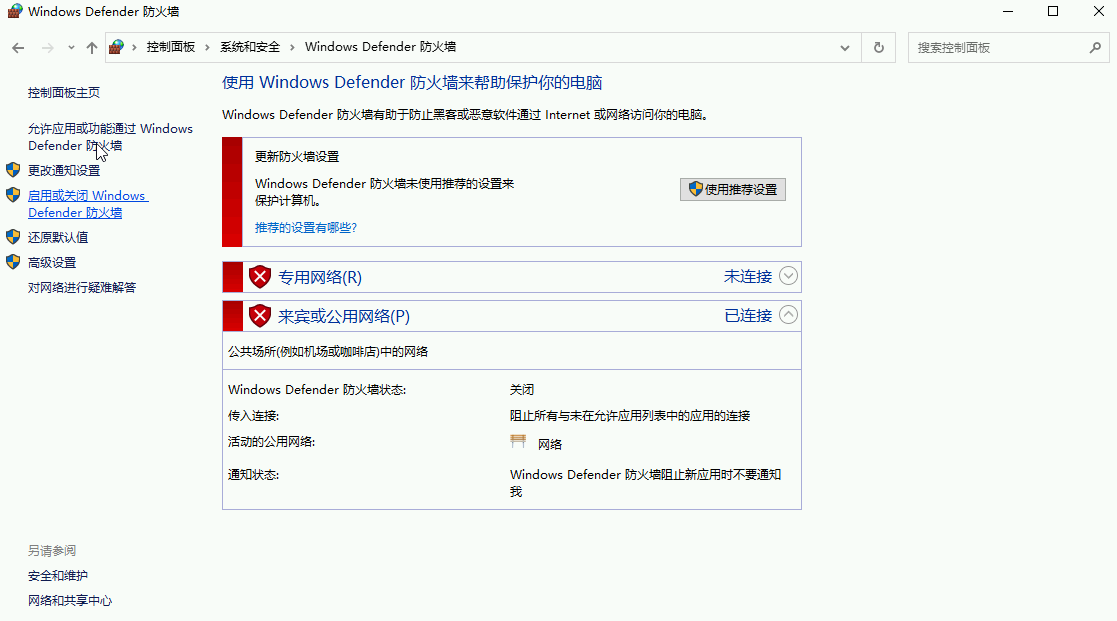
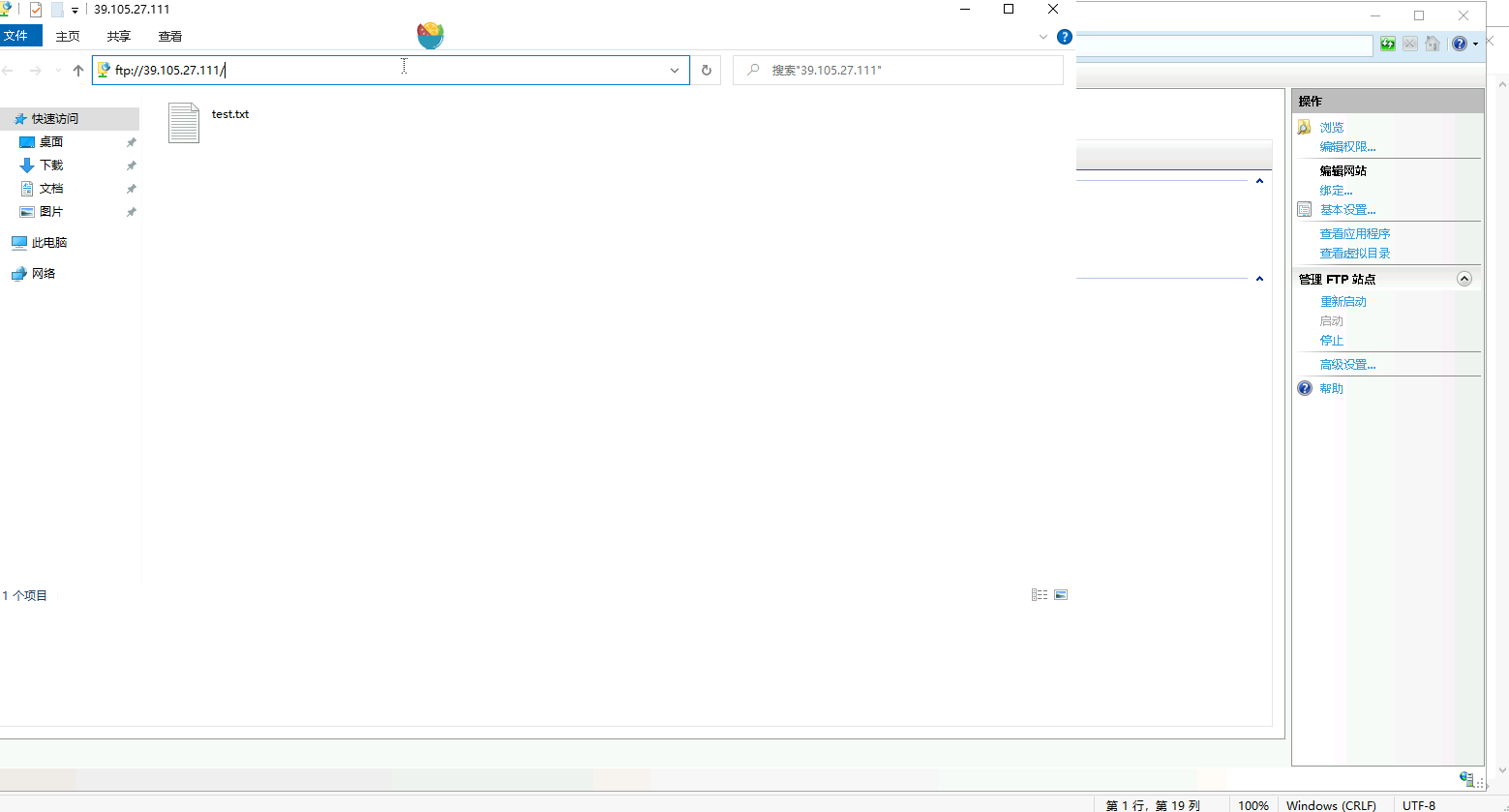
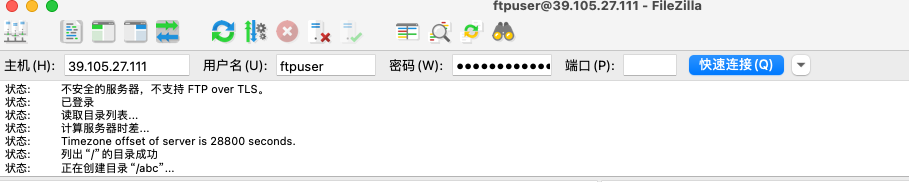
星空Storms make trees take deeper roots.2024-04-10T14:38:40.309Zhttps://blog.bosong.online/JackHexo在Windows Server 2022 服务器上搭建FTP站点https://blog.bosong.online/winserver-install-ftp.html2024-04-10T14:00:00.000Z2024-04-10T14:38:40.309Z前言
# This is a basic workflow to help you get started with Actions
name:SyncDokcerImageToAliyunRepo
# Controls when the action will run. on: # Triggers the workflow on push or pull request events but only for the master branch # push: # branches: [ master ]
# Allows you to run this workflow manually from the Actions tab
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: sync-task: # The type of runner that the job will run on runs-on:ubuntu-latest strategy: fail-fast:false matrix: include: -source_docker_image:mattermost/mattermost-enterprise-edition:7.5.0 target_docker_image:mattermost-enterprise-edition:7.5.0 -source_docker_image:nginx:latest target_docker_image:nginx:latest
# Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it -uses:actions/checkout@v2
# Runs a set of commands using the runners shell portainer/agent
jobs: sync-task: # The type of runner that the job will run on runs-on:ubuntu-latest strategy: fail-fast:false matrix: #接收Api的参数 images:'${{ github.event.client_payload.images }}'
# Steps represent a sequence of tasks that will be executed as part of the job steps: -uses:actions/checkout@v2 -name:sync${{matrix.images.source}} run:| docker pull $source_docker_image docker tag $source_docker_image $target_docker_image docker login --username=${{secrets.DOCKER_USERNAME}} --password=${{secrets.DOCKER_PASSWORD}} ${{secrets.DOCKER_REGISTRY}} docker push $target_docker_image env: source_docker_image:${{matrix.images.source}} target_docker_image:${{secrets.DOCKER_REGISTRY}}/${{secrets.DOCKER_NAMESPACE}}/${{matrix.images.target}}
## LINKACE CONFIGURATION LINKACE_VERSION=v1.10.4-php-nginx ## Basic app configuration COMPOSE_PROJECT_NAME=linkace # The app key is generated later, please leave it blank APP_KEY=
## Configuration of the database connection ## Attention: Those settings are configured during the web setup, please do not modify them now. # Set the database driver (mysql, pgsql, sqlsrv) DB_CONNECTION=mysql # Set the host of your database here DB_HOST=mysql-host # Set the port of your database here DB_PORT=3306 # Set the database name here DB_DATABASE=database # Set both username and password of the user accessing the database DB_USERNAME=username
DB_PASSWORD=password
## Redis cache configuration # Set the Redis connection here if you want to use it REDIS_HOST=host REDIS_PASSWORD= REDIS_PORT=6379
# Configure various driver SESSION_DRIVER=redis LOG_CHANNEL=stack BROADCAST_DRIVER=log CACHE_DRIVER=redis QUEUE_DRIVER=database
[root@tianyi-152 ~]# kubectl version --short Flag --short has been deprecated, and will be removed in the future. The --short output will become the default. Client Version: v1.25.3+k3s1 Kustomize Version: v4.5.7 Server Version: v1.25.3+k3s1
#查看所有的pod是不是completed 或者 running状态,如果是,那就是已正常启动 kubectl get pods -A #查看k3s集群的节点状态 [root@tianyi-152 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION tianyi-152 Ready control-plane,master 170m v1.25.3+k3s1
# The full public facing url you use in browser, used for redirects and emails # 这个配置为你的grafana地址,需要进行配置 root_url=https://grafana.abc.com # 如果仅限OAuth仅限登录的话设置为true(建议先设置为false,待修改OIDC的权限配置为admin之后再关闭) disable_login_form=true #################################### Generic OAuth ########################## [auth.generic_oauth] enabled=true name=authelia allow_sign_up=true client_id=grafana client_secret=GzPji9HrYbLQEX scopes=openidprofilegroupsemail empty_scopes=false auth_url=https://auth.example.com/api/oidc/authorization token_url=https://auth.example.com/api/oidc/token api_url=https://auth.example.com/oidc/userinfo use_pkce=true
# This is a basic workflow to help you get started with Actions
name:signle_repo_codeup2github
# Controls when the workflow will run on: #定时任务自动触发(最好和webhook的拆分为两个) #schedule: # - cron: 0 */12 * * * #使用github的webhook触发 repository_dispatch: types: -codeup_push
#手动触发 workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: repo-sync: env: dst_key:${{secrets.GIT_PRIVATE_KEY}} runs-on:ubuntu-latest steps: -uses:actions/checkout@v2 with: persist-credentials:false
# Controls when the workflow will run on: # Triggers the workflow on push or pull request events but only for the main branch push: # branches: [ main ] 注释代表全部分支、 schedule: - cron: 0 */12 * * *
# Allows you to run this workflow manually from the Actions tab workflow_dispatch:
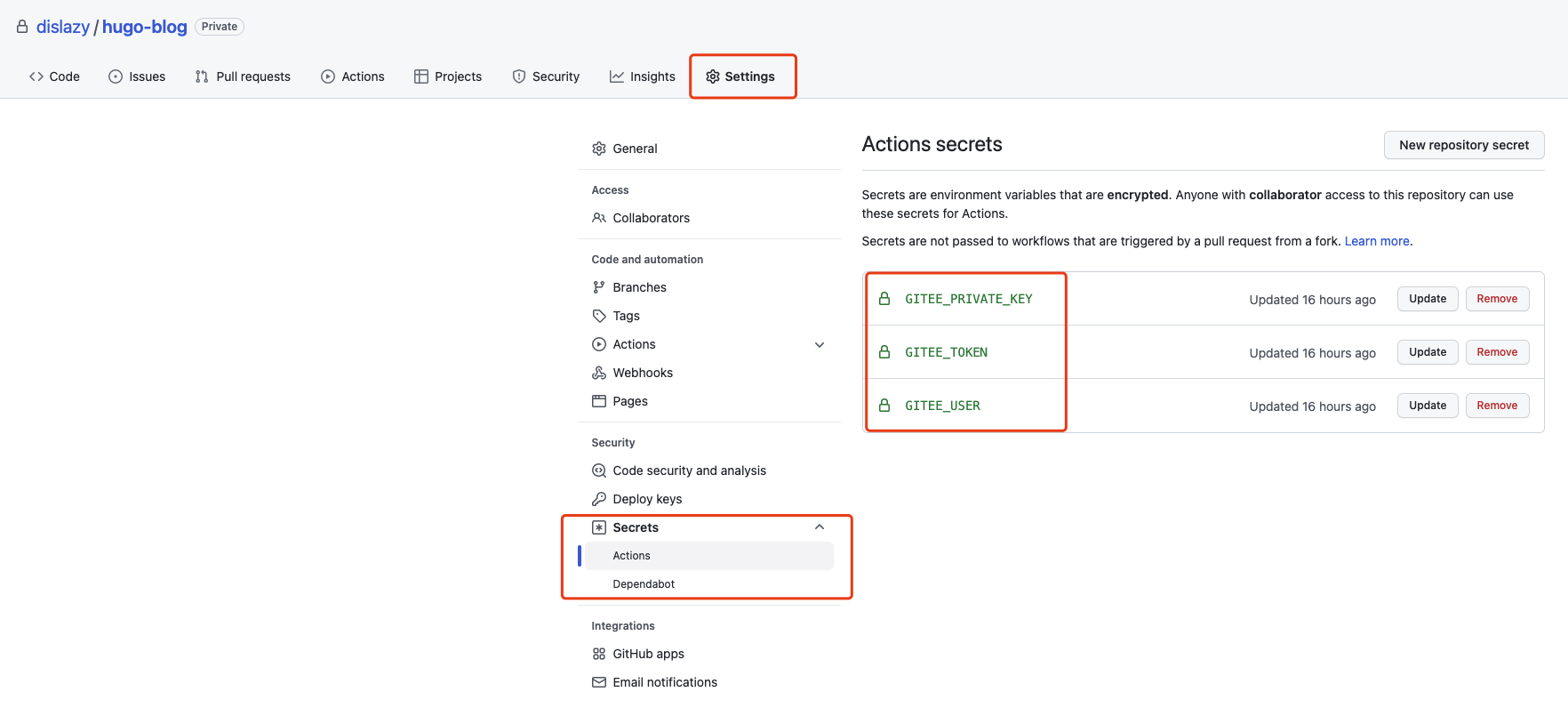
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: repo-sync: env: dst_key: ${{ secrets.GITEE_PRIVATE_KEY }} dst_token: ${{ secrets.GITEE_TOKEN }} gitee_user: ${{ secrets.GITEE_USER }} runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 with: persist-credentials: false
- name: Get Time id: get-time run: | echo "::set-output name=date::$(/bin/date -u "+%Y%m%d%H%M%S")" shell: bash
# This is a basic workflow to help you get started with Actions
name: signle_repo_github2gitee
# Controls when the workflow will run on: repository_dispatch: types: - github_push
# Allows you to run this workflow manually from the Actions tab workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: repo-sync: env: dst_key: ${{ secrets.GITEE_PRIVATE_KEY }} dst_token: ${{ secrets.GITEE_TOKEN }} gitee_user: ${{ secrets.GITEE_USER }} runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 with: persist-credentials: false
# This is a basic workflow to help you get started with Actions
name: webhook
# Controls when the workflow will run on: # 注释代表所有分支 push: # branches: [ main ]
# Allows you to run this workflow manually from the Actions tab workflow_dispatch: jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3
# Runs a set of commands using the runners shell - name: Run a multi-line script run: | curl \ -X POST \ -H "Accept: application/vnd.github.v3+json" \ -H "Authorization: token {{githubToken}}" \ https://api.github.com/repos/:owner/:repo/dispatches \ -d '{"event_type":"github_push","client_payload":{"repo":"${{ github.event.repository.name }}","message":"github action sync"}}' echo 'success'
# This is a basic workflow to help you get started with Actions
name:CI
# Controls when the workflow will run on: # Triggers the workflow on push or pull request events but only for the main branch push: branches: [ main ]
# Allows you to run this workflow manually from the Actions tab workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: repo-sync: env: dst_key:${{secrets.GITEE_PRIVATE_KEY}} dst_token:${{secrets.GITEE_TOKEN}} gitee_user:${{secrets.GITEE_USER}} runs-on:ubuntu-latest steps: -uses:actions/checkout@v2 with: persist-credentials:false